用不了多久,开源版的Sora就会涌来!理海大学微软团队已经做出一种全新多AI智能体框架Mora,可以完全复刻Sora能力,且生成视频效果几乎不相上下。
微软版Sora诞生了!
Sora虽爆火但闭源,给学术界带来了不小的挑战。学者们只能尝试使用逆向工程来对Sora复现或扩展。
尽管提出了Diffusion Transformer和空间patch策略,但想要达到Sora的性能还是很难,何况还缺乏算力和数据集。
不过,研究者发起的新一波复现Sora的冲锋,这不就来了么!
就在刚刚,理海大学联手微软团队一种新型的多AI智能体框架———Mora。

没错,理海大学和微软的思路,是靠AI智能体。
Mora更像是Sora的通才视频生成。通过整合多个SOTA的视觉AI智能体,来复现Sora展示的通用视频生成能力。
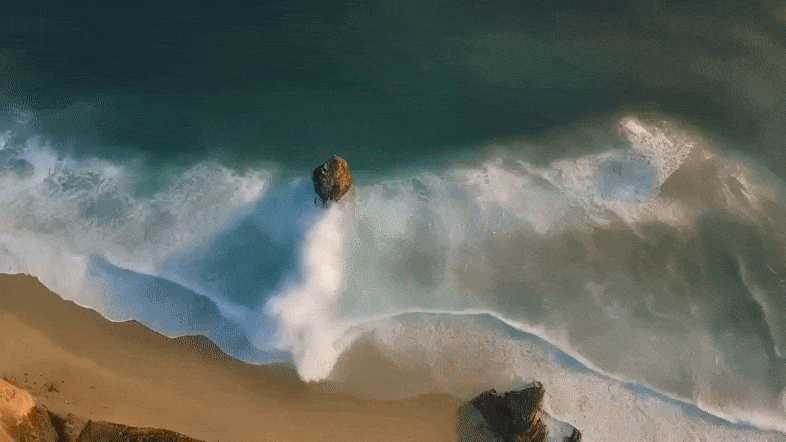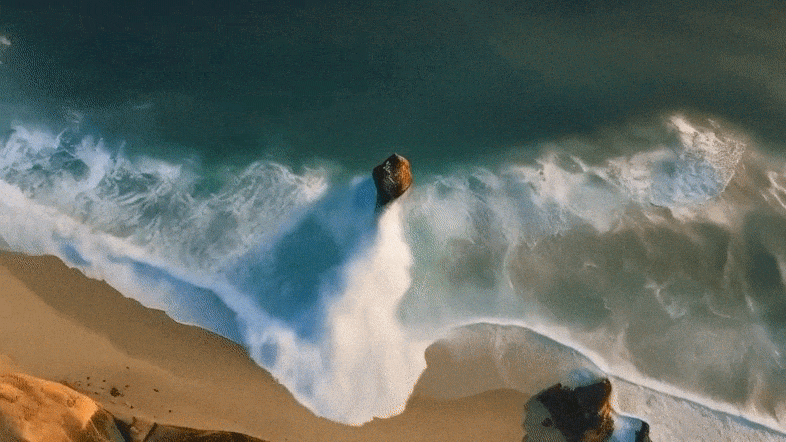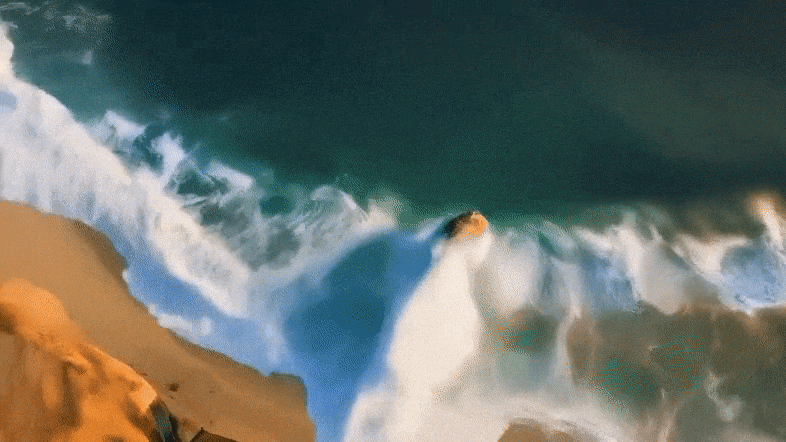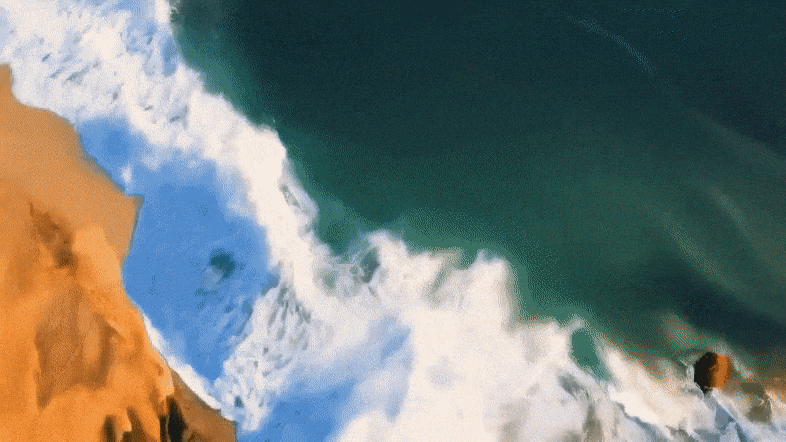
具体来说,Mora能够利用多个视觉智能体,在多种任务中成功模拟Sora的视频生成能力,包括:
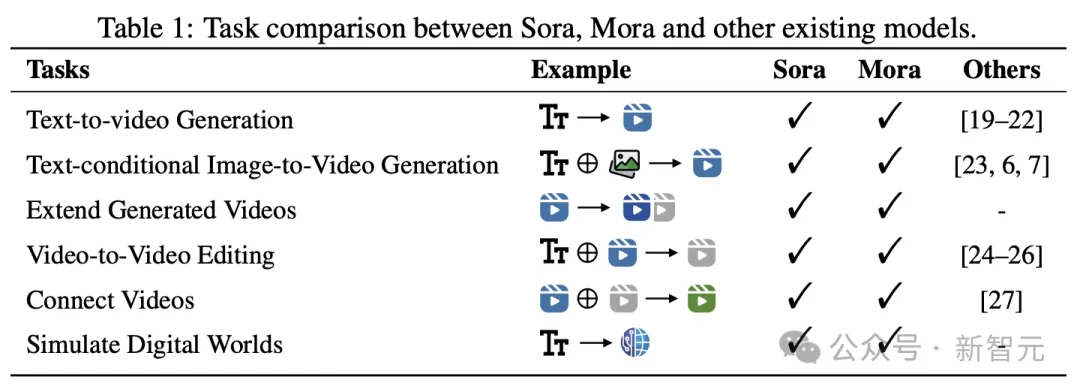
实验结果表明,Mora在这些任务中取得了接近Sora的表现。
值得一提的是,它在文本到视频生成任务中的表现超越了现有的开源模型,在所有模型中排名第二,仅次于Sora。
不过,在整体性能上,与Sora还有着明显差距。

复刻Sora所有能力
Mora基本上还原了Sora的所有能力,怎么体现?
文本到视频生成

提示:A vibrant coral reef teeming with life under the crystal-clear blue ocean, with colorful fish swimming among the coral, rays of sunlight filtering through the water, and a gentle current moving the sea plants.

提示:A majestic mountain range covered in snow, with the peaks touching the clouds and a crystal-clear lake at its base, reflecting the mountains and the sky, creating a breathtaking natural mirror.

提示:In the middle of a vast desert, a golden desert city appears on the horizon, its architecture a blend of ancient Egyptian and futuristic elements.The city is surrounded by a radiant energy barrier, while in the air, seve
基于文本条件图像到视频的生成
输入这张经典的「SORA字样的逼真云朵图像」。

提示:An image of a realistic cloud that spells “SORA”.
Sora模型生成的效果是这样的。

Mora生成出来的视频,丝毫不差。

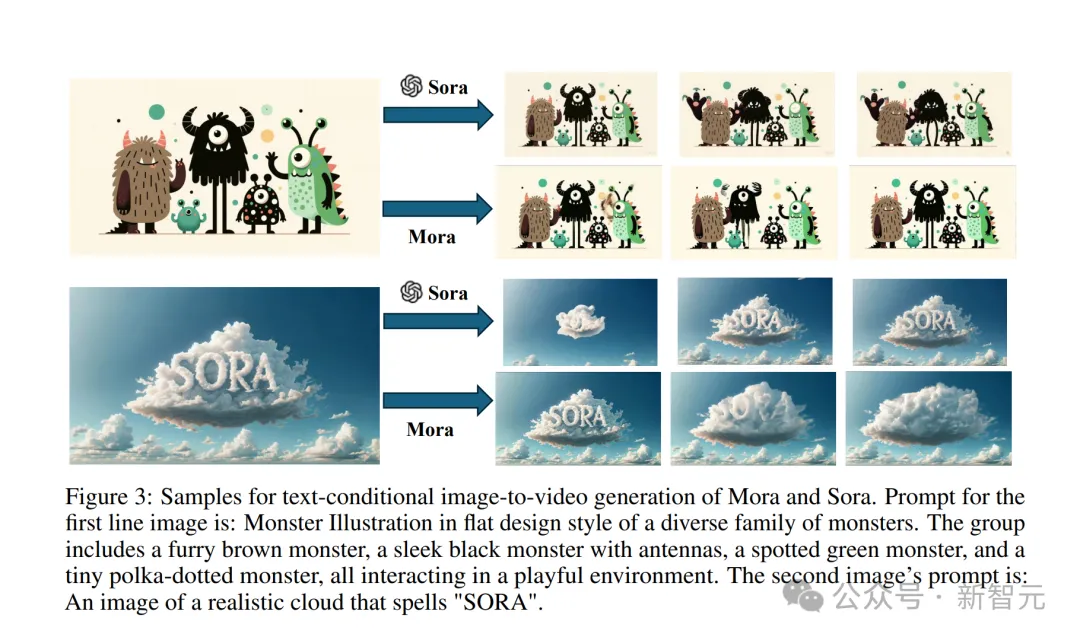
还有输入一张小怪兽图片。

提示:Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
Sora将其转换为视频的效果,让这些小怪兽们活灵活现动起来。

Mora虽也让小怪兽们动起来,但是明显可以看出有些不稳定,图中卡通人物样子没有保持一致。

扩展已生成的视频
先给到一个视频

Sora能够生成稳定的AI视频,而且风格一致。

但Mora生成的视频中,前面骑自行车的人最后自行车没了,人也变形了,效果不是很好。

视频到视频编辑
给到一个提示「将场景切换到20世纪20年代的老式汽车」,并输入一个视频。

Sora经过风格替换后,整体看起来非常丝滑。

Mora这段老式汽车的生成,破旧的有点不真实。

拼接视频
输入两个视频,然后将其完成拼接。


Mora拼接后的视频

模拟数字世界

整体接近,但不如Sora
一大波演示之后,大家对Mora的视频生成能力有了一定了解。
与OpenAI Sora相比,Mora在六个任务中的表现非常接近,不过也存在着很大的不足。
文本到视频生成
具体来说,Mora的视频质量得分0.792,仅次于第一名Sora的0.797,并且超过了当前最好的开源模型(如VideoCrafter1)。
在对象一致性方面,Mora得分0.95,与Sora持平,在整个视频中都表现出了卓越的一致性。
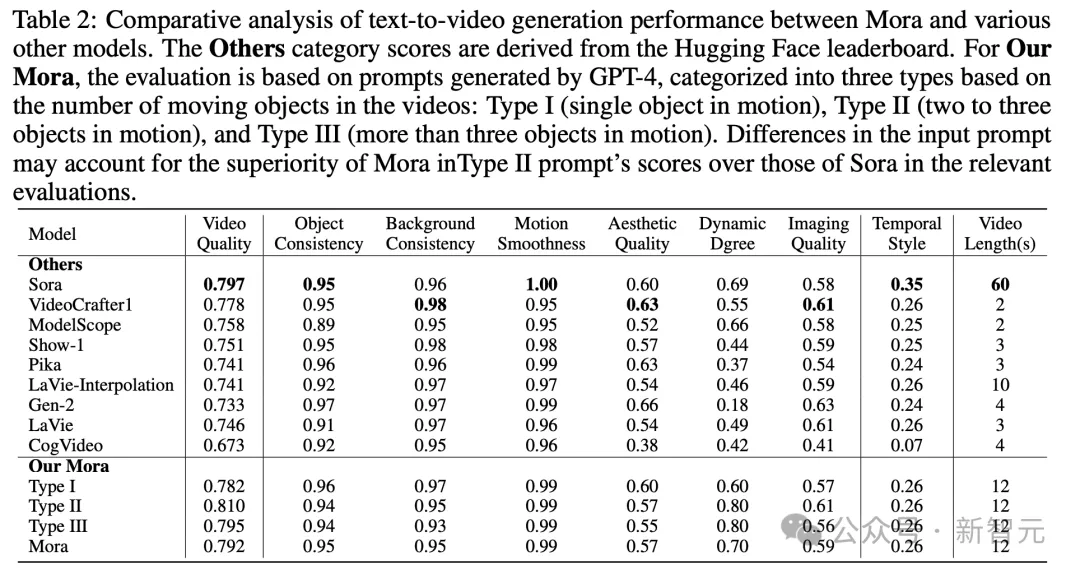
在下图中,Mora文本到视频生成的视觉保真度非常引人注目,体现了高分辨率图像以及对细节的敏锐关注,和对场景的生动描绘。

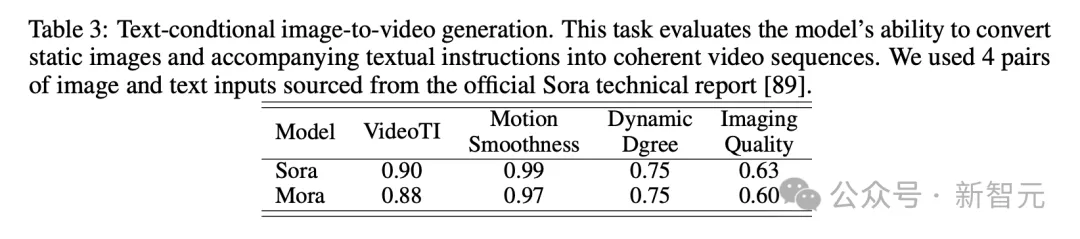
在基于文本条件的图像生成任务中,模型在将图片和文本指令,转化成连贯视频能力上,Sora肯定是最完美的。
不过Mora的结果,与Sora相差很小。
扩展生成的视频
再来看扩展生成视频测试中,在连续性和质量上的结果,也是Mora与Sora比较接近。
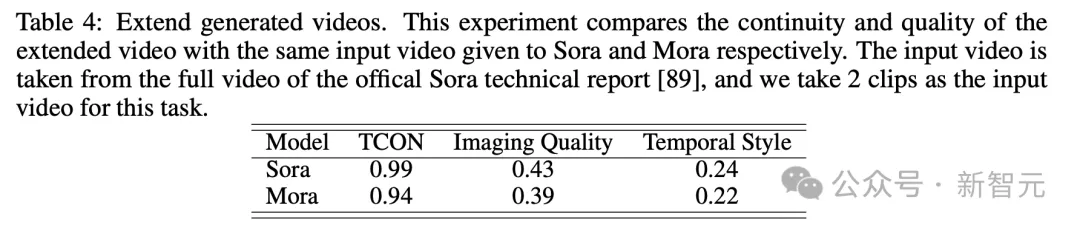
尽管Sora处于领先地位,但Mora的能力,特别是在遵循时间风格和扩展现有视频而不显著损失质量方面,证明了其在视频扩展领域的有效性。

视频到视频编辑+视频拼接
针对视频到视频编辑,Mora在保持视觉和风格连贯性的能力方面接近Sora。还有拼接视频任务中,Mora也可以实现将不同视频进行无缝拼接。
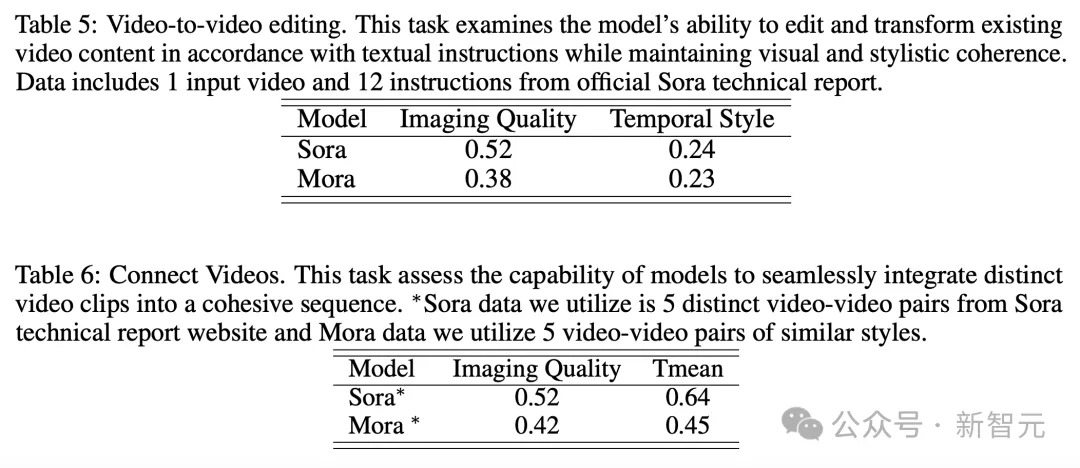
在这个示例中,Sora和Mora都被指示将设置修改为1920年代风格,同时保持汽车的红色。


模拟数字世界
还有最后的模拟数字世界的任务,Mora也能像Sora一样具备创建虚拟环境世界的能力。不过质量方面,比Sora差一些。


Mora:基于智能体的视频生成
Mora这个多智能体框架,是如何解决当前视频生成模型的局限的?
它的关键,就是通过将视频生成过程分解为多个子任务,并为每个任务指派专门的智能体,来灵活地完成一系列视频生成任务,满足用户的多样化需求。
在推理过程中,Mora会生成一个中间图像或视频,从而保持文本到图像模型中的视觉多样性、风格和质量,并增强编辑功能。

通过高效地协调处理从文本到图像、从图像到图像、从图像到视频以及从视频到视频的转换任务的智能体,Mora能够处理一系列复杂的视频生成任务,提供出色的编辑灵活性和视觉真实度。
总结来说,团队的主要贡献如下:
– 创新性的多智能体框架,以及一个直观的界面,方便用户配置不同的组件和安排任务流程。
– 作者发现,通过多个智能体的协同工作(包括将文本转换成图像、图像转换成视频等),可以显著提升视频的生成质量。这一过程从文本开始,先转化为图像,然后将图像和文本一起转换成视频,最后对视频进行优化和编辑。
– Mora在6个与视频相关的任务中都展现出了卓越的性能,超过了现有的开源模型。这不仅证明了Mora的高效性,也展示了其作为一个多用途框架的潜力。
智能体的定义
在视频生成的不同任务中,通常需要多个具有不同专长的智能体协同工作,每个智能体都提供其专业领域的输出。
为此,作者定义了5种基本类型的智能体:提示选择与生成、文本到图像生成、图像到图像生成、图像到视频生成、以及视频到视频生成。
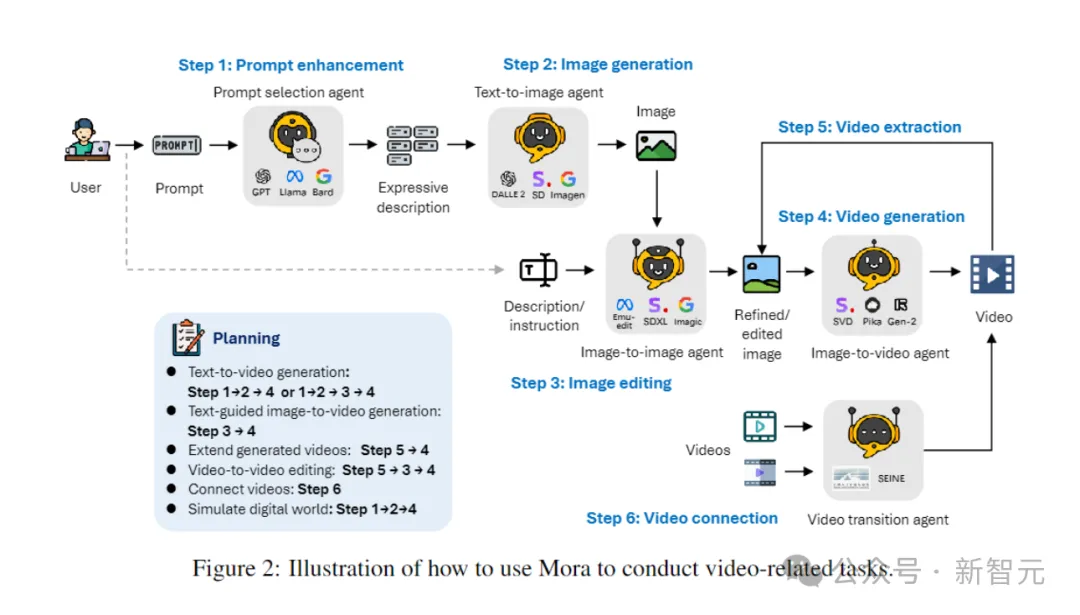
– 提示选择与生成智能体:
在开始生成初始图像之前,文本提示会经过一系列严格的处理和优化步骤。这个智能体可以利用大型语言模型(如GPT-4)来精确分析文本,提取关键信息和动作,大大提高生成图像的相关性和质量。
– 文本到图像生成智能体:
这个智能体负责将丰富的文本描述转化为高质量的图像。它的核心功能是深入理解和可视化复杂的文本输入,从而能够根据提供的文本描述创建详细、准确的视觉图像。
– 图像到图像生成智能体:
根据特定的文本指令修改已有的源图像。它能够精确解读文本提示,并据此调整源图像(从细微修改到彻底改造)。通过使用预训练模型,它能够将文本描述与视觉表现有效拼接,实现新元素的整合、视觉风格的调整或图像构成的改变。
– 图像到视频生成智能体:
在初始图像生成之后,这个智能体负责将静态图像转化为动态视频。它通过分析初始图像的内容和风格,生成后续的帧,确保视频的连贯性和视觉一致性,展现了模型理解、复制初始图像,以及预见并实现场景逻辑发展的能力。
– 视频拼接智能体:
这个智能体通过选择性使用两段视频的关键帧,确保它们之间平滑且视觉上一致的过渡。它能够准确识别两个视频中的共同元素和风格,生成既连贯又具有视觉吸引力的视频。
智能体的实现
文本到图像的生成
研究者利用预训练的大型文本到图像模型,来生成高质量且具有代表性的第一张图像。
第一个实现,用的是Stable Diffusion XL。
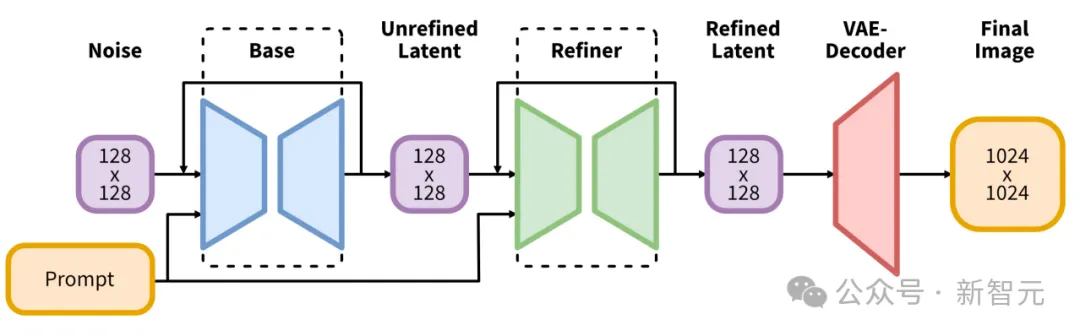
它引入了文本到图像合成的潜在扩散模型的架构和方法的重大演变,在该领域树立了新的基准。
其架构的核心,就是一个扩大的UNet主干网络,它比Stable Diffusion 2之前版本中使用的主干大三倍。
这种扩展主要是通过增加注意力块的数量和更广泛的交叉注意力上下文来实现的,并通过集成双文本编码器系统来促进。
第一个编码器基于OpenCLIP ViT-bigG,而第二个编码器则利用CLIP ViT-L,通过拼接这些编码器的输出,来允许对文本输入进行更丰富、更细致的解释。

这种架构创新辅以多种新颖的调节方案的引入,这些方案不需要外部监督,从而增强了模型的灵活性和生成跨多个长宽比的图像的能力。
此外,SDXL还具有一个细化模型,该模型采用事后图像到图像转换来提高生成图像的视觉质量。
此细化过程利用噪声去噪技术,进一步完善输出图像,而不会影响生成过程的效率或速度。
图像到图像的生成
在这个过程中,研究者用初始框架,实现了使用InstructPix2Pix作为图像到图像生成智能体。

InstructPix2Pix经过精心设计,可以根据自然语言指令进行有效的图像编辑。
该系统的核心集成了两个预训练模型的广泛知识:GPT-3用于根据文本描述生成编辑指令和编辑后的标题;Stable Diffusion用于将这些基于文本的输入转换为视觉输出。
这种巧妙的方法首先在精选的图像标题数据集和相应的编辑指令上微调GPT-3,从而产生一个可以创造性地建议合理编辑并生成修改后的标题的模型。
在此之后,通过Prompt-to-Prompt技术增强的Stable Diffusion模型,会根据GPT-3生成的字幕生成图像对(编辑前和后)。
然后在生成的数据集上训练InstructPix2Pix核心的条件扩散模型。
InstructPix2Pix直接利用文本指令和输入图像,在单次前向传递中执行编辑。
通过对图像和指令条件采用无分类器指导,进一步提高了这种效率,使模型能够平衡原始像的保真度和遵守编辑指令。
图像到视频的生成
在文本到视频生成智能体中,视频生成代理在确保视频质量和一致性方面发挥着重要作用。
研究者的第一个实现,是利用目前的SOTA视频生成模型Stable Video Diffusion来生成视频。

SVD架构利用最初为图像合成而开发的LDMs Stable Diffusion v2.1的优势,将其功能扩展到处理视频内容固有的时间复杂性,从而引入了一种生成高分辨率视频的先进方法。
SVD模型的核心遵循三阶段训练体系,从文本到图像相关开始,模型从一组不同的图像中学习稳健的视觉表示。这个基础,使模型能够理解并生成复杂的视觉图案和纹理。
在第二阶段,即视频预训练中,模型接触大量视频数据,使其能够通过将时间卷积和注意力层与其空间对应层结合起来来学习时间动态和运动模式。
训练是在系统管理的数据集上进行的,确保模型从高质量且相关的视频内容中学习。
最后阶段是高质量视频微调,重点是改进模型使用更小但更高质量的数据集,生成分辨率和保真度更高的视频的能力。
这种分层训练策略辅以新颖的数据管理流程,使SVD能够出色地生成最先进的文本到视频和图像到视频合成,并且随着时间的推移,具有非凡的细节、真实性和连贯性。
拼接视频
对于这个任务,研究者利用SEINE来拼接视频。
SEINE是基于预训练的T2V模型LaVie智能体构建的。
SEINE以随机掩码视频扩散模型为中心,后者根据文本描述生成过渡。
通过将不同场景的像与基于文本的控制相集成,SEINE可以生成保持连贯性和视觉质量的过渡视频。
此外,该模型还可以扩展到图像到视频动画和白回归视频预测等任务。
讨论
优势
– 创新框架与灵活性:
Mora引进了一种革命性的多智能体视频生成框架,大大拓展了此领域的可能性,使得执行各种任务变得可能。
它不仅简化了将文本转换成视频的过程,还能模拟出数字世界,展现出前所未有的灵活性和效率。
– 开源贡献:
Mora的开源特性是对AI社区一个重要的贡献,它通过提供一个坚实的基础,鼓励进一步的发展和完善,为未来的研究奠定了基础。
如此一来,不仅可以让高级视频生成技术更加普及,还促进了该领域内的合作和创新。
局限性
– 视频数据至关重要:
想捕捉人类动作的细微差别,就需要高分辨率、流畅的视频序列。这样才能够详细展现动力学的各个方面,包括平衡、姿势及与环境的互动。
但高质量的视频数据集多来源于如电影、电视节目和专有游戏画面等专业渠道。其中往往包含受版权保护的材料,不易合法收集或使用。
而缺乏这些数据集,使得像Mora这样的视频生成模型难以模拟人类在现实环境中的动作,如走路或骑自行车。
– 质量与长度的差距:
Mora虽然可以完成类似Sora的任务,但在涉及大量物体移动的场景中,生成的视频质量明显不高,质量随视频长度增加而降低,尤其是在超过12秒之后。
– 指令跟随能力:
Mora虽然可以在视频中包含提示所指定的所有对象,但它难以准确解释和展示提示中描述的运动动态,比如移动速度。
此外,Mora还不能控制对象的运动方向,比如无法让对象向左或向右移动。
这些局限主要是因为Mora的视频生成,是基于图像转视频的方法,而不是直接从文本提示中获取指令。
– 人类偏好对齐:
由于视频领域缺少人类的标注信息,实验结果可能并不总是符合人类的视觉偏好。
举个例子,上面其中的一个视频拼接任务,要求生成一个男性逐渐变成女性的过渡视频,看起来非常不合逻辑。
内容转自公众号「新智元」
相关文章

 渝公网安备50010802005100
渝公网安备50010802005100